
Différents sujets sont abordés récemment sur les pratiques à mettre en place pour une avoir une infrastructure fiable, scalable, et qui respectent certaines contraintes.
D’une perspective business, le plus important est d’avoir une application fiable. Si l’application que vous proposez ne l’est pas, vous aurez moins de clients et donc automatiquement moins de plus-value générée à travers votre application ou service.
Pour fournir des applications fiables, Google à mis en place un pratique : le SRE ( Site Reliability Engineering). Nous allons aborder différents points pour comprendre les différents aspects de cette pratique.
1 — Définition du SRE
Comme nous l’avions évoqué, le plus important pour une application c’est d’être fiable, la fiabilité implique disponibilité et scalabilité. En plus d’être fiable, une application doit être dans une logique d’amélioration continue pour faire face à la concurrence, ce qui implique, techniquement, des releases plus fréquentes.
Tout l’enjeu du SRE est de faire cohabiter fiabilité et amélioration continue de l’application.
C’est pour garantir des releases plus rapides et stables que la pratique du SRE intervient.
Le SRE est une pratique particulière du DevOps, en java on pourrait dire que la classe SRE implémente l’interface DevOps.
C’est l’approche de Google pour faire fonctionner leurs applications en productions en gardant l’équilibre entre innovation et qualité de service.
Chez Google,une équipe SRE, est composée d’ingénieurs plus orientés développements que opérations. Ce sont des développeurs exerçant les tâches d’un OPS.
2 — Error Budget, SLI et SLO :
L’ “Error Budget” est la clé du SRE. L’ “Error Budget“ consiste à calculer le taux d’indisponibilité que nous pouvons tolérer pour un systéme.
Il s’agit donc de définir le taux de disponibilité maximale que nous voulons atteindre et de se servir de l’écart entre le taux de disponibilité souhaité et le taux de disponibilté maximale (100%) pour innover ou améliorer un produit.
Voici un exemple qui explique le principe du “Error Budget” :
1 — Définir un taux de disponbilité souhaité, par exemple 99,9%, notre site internet doit donc etre disponible 99,9% pendant le mois.
2 — Calculer l’error budget : 100% — 99,9% = 0,1% donc 43,2 min / mois, ce qui représente le temps durant un mois pendant lequel notre site peut etre disponible.
3 — Une fois l’error budget calculé il faut monitorer l’évolution de cet error budget pour pouvoir ensuite faire les actions nécessaire.
- Si on a encore de l’error budget = les devs peuvent encore pusher des releases
- Si nous avons depensé tout notre error budget = pas de nouvelles realeases
- Si nous avons tout l’error budget qui est encore disponible = pas assez d’innovations
Ce calcul permet de définir une marge pour l’équipe de développement afin d’innover, ça leur permet de manager ce risque et d’avoir une responsabilité partagée entre l’équipe de développement et les ops, pusique, les erreurs liées à l’infrastructure consomment l’error budget des développeurs.
“Error Budget” permet d’avoir un équilibre entre innovation et fiabilité de l’infrastructure en place.
Trois indicateurs sont la pour vous aider à mesurer vos efforts en SRE et notre “Error Budget” :
- SLA : Service Level Agreement, C’est la disponibilié et la fiabilité requise par le client final ou l’utisateur du service
- SLO : Service Level Objective, c’est l’objectif que l’on voudrait atteindre pour un service, le SLO est un objectif interne et n’est pas partagé avec le client.
- SLI : Service Level Indicator, utilisé pour calculer le SLO et définir le service “minimum” pour satisfaire le SLO.
Prenons comme exemple un service d’API qui notifie ces utilisateurs par SMS
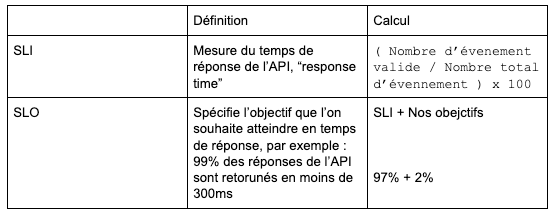
3 — Le SRE en pratique
Le SRE dans la pratique se compose autour de 4 sujets qui sont :
- Monitoring et Alerting : Automatiser le monitoring et mise en place de KPI, notifier immédiatement en cas d’anomalie, ne faire intervenir un ingénieur que dans le cas ou le SLO est menacée.
- Capacity planning : Prévoir à l’avance les différents scalingà mettre en place, et anticiper l’usage intensif d’un service
- Change Management : Détecter les problèmes rapidement, mettre en place des procédures de rollback et automatiser au maximum les procédures
- Emergency Response : définir un incident et mise en place de postmortem pour avoir un feedback et documenter l’incident
Une équipe de SRE est idéalement composé d’ingénieurs capables de faire du code et aussi de l’ops. Ce sont des profils polyvalents.
Le DevOps est un ensemble de pratiques et une culture qui permet de casser les silos entre le ops et les dev. Le SRE implémente le devops en rajoutant des pratiques et en définissant un role clair au sein d’une équipe avec des ingénieurs SRE qui ont un profil polyvalent.