
The speed at which your application responds, and its availability, are two critical aspects of your user experience.
When you use serverless, the performance of your application not only impacts your user experience but also your costs.
With AWS Lambda, billing depends on how long your function runs, weighted by the memory you assign to it.
Serverless, and in particular Lambda, eliminates many possibilities for optimizing performance, such as scaling or modifying server configurations.
This makes it difficult for new users to understand how to proceed in order to have efficient and inexpensive serverless functions.
In this article we will introduce you to the main tools and approaches that we use within PISQUARE to improve the performance of AWS Lambda functions and thus reduce the costs associated with their use.
What are the steps that are performed when an AWS Lambda function is called?
Before explaining how to optimize Lambdas functions, we must first have in mind the different steps that are executed once the function is called.
The following figure shows the different steps:
1- Downloading your lambda into the compute layer
2 – Creating a new runtime environment
3 – Instantiating dependencies and runtime
4 – Assigning the environment to the query
5 – Code execution
6 – Unassign the execution environment
7 – Cached execution environment (variable time)
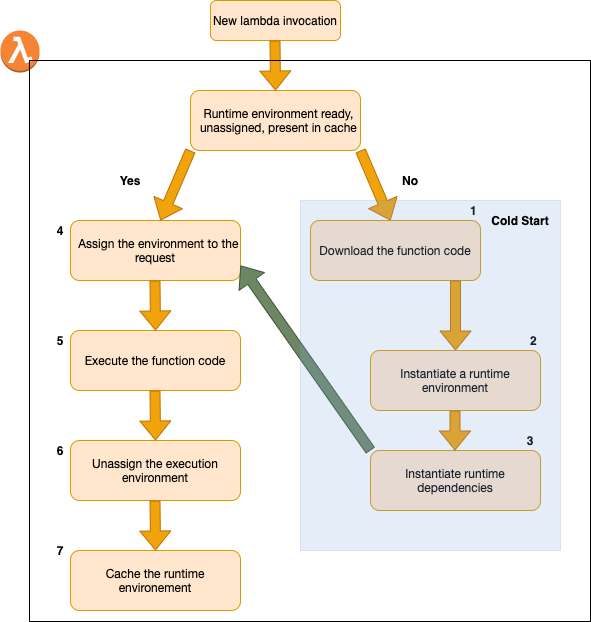
Once the lambda function is called, it will first of all check if an execution environment is present in the cache, if this is the case, the environment will be assigned to the request and the function code will be executed.
On the other hand, if the lambda does not find the environment which corresponds to the call in the cache, the code of the function will be downloaded again and a new execution environment will be instantiated. AWS has not published an exact time to create a new environment, but in our experience this can vary between 5 and 20 minutes.
The latency of serverless applications and that of lambdas in particular has a direct impact on the cost of functions and on the user experience.
Cold Start vs Warm Start
The process described above reflects the different causes of Cold and Warm Start.
A Cold Start penalty, which results in a longer function execution time, occurs in three situations:
- The lambda function is called for the first time
- The lambda function is called after a long time since its last execution
- If the number of requests is too high, forcing AWS Lambda to instantiate new runtime environments.
Warm start is the opposite of cold start, it results in a fairly short execution time due to an environment and a code present in the cache.
In order to optimize the latency and the cost of our lambda functions, we are working on three aspects in order to reduce the cold start as much as possible and obtain the shortest possible execution time:
- The size of the artifact (of the compressed code that we deploy)
- The caliber of the runtime environment
- The code for function
1 – Minimize the size of the artifact:
The size of your deployment package has a direct impact on the cold start (time taken by the lambda to download the code and instantiate a runtime environment).
The larger the code, the longer the cold start and the greater the latency.
In order to reduce the size of the artifact it is necessary to audit all the dependencies of the function:
Are there heavy library dependencies to remove or light versions that can be used?
Especially look for libraries that act as servers or HTTP agents as they have no use in Lambda functions, since Lambda acts as the server for you.
At PISQUARE our auditions our dependencies for Node using tools such as https://npm.anvaka.com/, or for Python using https://pypi.org/project/modulegraph/. This allows us to considerably reduce the size of the code.
2 – Calibrating the execution environment
The lambda code requires computation resources (CPU, memory) to be executed.
AWS Lambda provides only one option to define the resources required by your function: the memory parameter.
AWS Lambda allocates processor power proportionally to memory using the same ratio as a general-purpose Amazon EC2 instance type such as an M3 type.
For example, if you allocate 256MB of memory, your Lambda function will receive twice the CPU share than if you allocated only 128MB.
AWS Lambda pricing weights the time charged for your function based on its memory setting. So 1 second of function execution time at 1024MB costs the same as 8 seconds of running time at 128MB.
Finding the right resource allocation for your function will take some experimentation.
The easiest path is to start with a high setting and lower it until you see a change in the performance characteristics.
A good allocation of the execution environment will thus make it possible to avoid instantiating new environments unnecessarily which could increase the latency (cold start) and the cost.
3 – Optimize Function Code
AWS Lambda charges your usage based on when your function starts running until when it stops, not based on spent CPU cycles or any other metric based in the time.
This implies that what your function does during it matters.
Consider the Image Resize Service feature: When you download the S3 object, your code is just waiting for the S3 service to respond, and you pay for that wait.
In the case of this function, the time spent is negligible, but this wait time may become excessive for services that have long response times (for example, waiting for an EC2 instance being provisioned) or waiting times (such as downloading a very large file). There are two options to minimize this idle time:
Minimize orchestration in code:
Instead of waiting for an operation in your function, use the AWS Step Functions to separate the “before” and “after” logic in half separate functions.
For example, if you have logic that needs to run before and after an API call, sequence them as two separate functions and use an AWS Step function to orchestrate between them.
Use threads for I / O intensive operations:
You can use multiple threads in a Lambda function (if the programming language supports it), just like code running in any compute environment. However, unlike conventional programs, the best use of multi-threading is not the parallelization of calculations.
This is because Lambda does not allocate multiple cores to Lambda functions running with less than 1.8 GB of memory, so you must allocate more resources to benefit from parallelization.
Instead, you can use threads to parallelize I / O operations. For example, a python version of the image_resizer function could act on multiple functions by performing the S3 download on a separate thread for the thumbnail.
By following these best practices, you can dramatically reduce the latency (and cost!) Of your serverless application.
Serverless offers a lot of possibilities, but can generate an expensive bill if the best practices are not put in place.
At PISQUARE we are implementing these good FinOps and development practices in order to optimize the cost of infrastructures and applications as much as possible.